| |
| Research article - (2024)23, 744 - 753 DOI: https://doi.org/10.52082/jssm.2024.744 |
| Prediction of Perceived Exertion Ratings in National Level Soccer Players Using Wearable Sensor Data and Machine Learning Techniques |
Robert Leppich1, Philipp Kunz2, André Bauer3, Samuel Kounev1, Billy Sperlich2, Peter Düking4, |
|
Narrated in English
|
 |
| Key words: Machine learning, artificial intelligence, RPE, elite athletes, monitoring, training prescription |
| Key Points |
|
|
|
| Participants |
26 healthy male national level soccer players (Tier 3 level according to a performance framework by (McKay et al., |
| External and internal load data collection |
During every training session (n = 5402) and each match (n = 732) of the 2019/2020 season, all players were equipped with a sensor of the Polar Team Pro System (Polar Electro Oy, Kempele, Finnland) to monitor heart rate data (60 Hz), accelerometry (100 Hz), and GPS-derived data (10 Hz). Each player was mandated to self-assess their RPE using a standardized 0-10 scale within an hour after every training session or match. During regular seasonal testing procedures of players, their individual maximal heart rate was determined in a standardized incremental test (starting at 7 km·h-1, increasing by 1 km·h-1 every minute) performed on a treadmill until full volitional exhaustion. Heart rate was measured using a Polar H10 sensor. |
| Feature engineering process |
Our analysis involved the calculation of 174 parameters (referred to as features) derived from GPS-units, heart rate sensors, and inertial measurement units. We use the reported RPE values of each player to train a machine learning model based on the engineered features in a supervised learning task (LeCun et al., |
| Data analysis and feature engineering |
Data acquisition was facilitated through the Polar Team API, which enabled the transfer of data into a local MongoDB database (version 4.4.8). Subsequent data processing and analysis were carried out using Python (version 3.10) and the Pandas library (version 1.4.4). A comprehensive set of 174 internal and external load parameters was calculated, as detailed in From the recorded heart rate, we derive various quantitative features, such as the mean, median, standard deviation, minimum, and maximum values. To establish heart rate zones, we utilize the individual maximum heart rate (HRmax) of each player. Each heart rate zone was defined as follows: Zone 1 = <30% HRmax, Zone 2 = 30-39% HRmax, Zone 3 = 40-49% HRmax, Zone 4 = 50-59% HRmax, Zone 5 = 60-71% HRmax, Zone 6 = 72-81% HRmax, Zone 7 = 82-87% HRmax, Zone 8 = 88-92% HRmax, Zone 9 = >92% HRmax. (Seiler, We included statistics and other calculated features that represent the absolute, percentage and periodicity values of time spent in each zone. In order to eliminate artifacts, here we define a period as a single subsequence (longer 1 sec) within a session. The training impulse (TRIMP) was calculated as described by e.g. (Calvert et al., Parameters related to external load where obtained using the Polar Team Pro System as detailed above. Features related to GPS and inertial measurement units in our analysis encompass statistical measures such as mean, median, standard deviation, and interquartile range, alongside kinetic energy, count of values surpassing the mean, and the extreme values. For categorizing speed zones, we followed the classification proposed by (Gualtieri et al., In addition, we incorporated a comprehensive set of features to capture covered distance and duration during high-intensity running (HIR) defined as velocities exceeding 14.4 km/h according to the definition provided by Coutts et al. ( |
| Statistical analysis Machine learning models |
For predicting RPE using our engineered features, we utilized ordinal regression across various machine learning models, as detailed in All machine learning models were adapted from the Scikit-learn library (v1.1.2, |
| Training of machine learning models |
Our training methodology for the machine learning models starts with splitting our dataset into two subsets: training and test sets. To enhance the robustness of our evaluation, we employed n-fold cross-validation. This technique iteratively partitions the dataset n times, varying the test set composition in each iteration to ensure every data point is included exactly once in the test set. This strategic procedure ensured the independence of results from the test dataset split. Specifically, we opted for a 5-fold cross-validation to ensure a sizable and representative test group for our analysis. The training dataset formed the basis for training the machine learning model, with the anticipated RPE serving as the target in a supervised learning framework. To enhance our model's performance, we implemented a randomized grid-search approach for optimal machine learning model configuration (Bergstra and Bengio, |
| Design of Artificial Neural Networks (ANN) |
The training and evaluation of the ANN closely mirrored the machine learning process described before. As an additional step in the ANN training process, the training dataset was further partitioned into a training dataset (80%) and a validation dataset (20%). In the training phase of the ANN, the model's performance was evaluated at each epoch using the validation dataset. The goal was to pinpoint the epoch where the ANN demonstrated peak performance. This involved tracking various performance metrics to confirm the model's effective learning from the training dataset, while avoiding overfitting. Overfitting occurs when a model becomes overly specialized to the training data, compromising its generalizability to new, unseen data. By scrutinizing the performance on the validation dataset across epochs, we pinpointed the epoch with the optimal model performance and made informed decisions regarding the model's generalization capabilities. This careful validation process was essential for ensuring the NN's robustness and its ability to make accurate predictions beyond the training dataset (Ripley, The deep learning model composed of multiple fully connected feed-forward layers, activation functions and residual connections (Chollet, Input stack: This initial component of the network served to transform the input dimension into a higher dimension denoted as "d_encode." It achieved this through a sequence of two feed-forward layers; Middle blocks: The central portion of the network comprises N identical blocks. Each of these blocks encompasses two feed-forward layers, each of which is enveloped by a sigmoid activation function, and a dropout layer is interposed between them. These blocks also feature a pivotal component where the output is augmented with a residual connection from the inception of the block. Additionally, layer normalization, as outlined by Lei Ba et al. ( Last layers: The concluding segment of the model consists of three feed-forward layers that further transform the dimensionality from "d_encode" into the final output of the model. The optimization process was conducted using the Adam optimizer, as detailed by Kingma and Ba (Kingma and Ba, |
| Experimental setup |
To ensure consistent training of the machine learning and deep learning models, we applied min-max normalization to each feature, scaling them between 0 and 1. The dataset was shuffled using a fixed seed to maintain reproducibility. We trained all models using 5-fold cross-validation, securing test split independence in our results. The reported scores represent the mean and standard deviation across all cross-validation splits. To balance the distribution of RPE target values, we performed oversampling for each dataset split, utilizing the Synthetic Minority Over-sampling Technique (SMOTE) (Lemaitre et al., To ensure an equal distribution of the RPE values during model training, oversampling of the dataset was performed. The distribution of the RPE values in the raw dataset is highly unbalanced ( Our detailed data analysis revealed an uneven distribution of RPE values throughout the dataset, both in the complete dataset and in a subset excluding games. To address this imbalance, we divided our experiments into two separate datasets: one inclusive of all data and the other excluding games. This division enabled us to perform tailored evaluations for each dataset, aligning our analysis with the specific conditions of each dataset. For the dataset including games, we introduced an innovative feature to quantify each player's total playtime. This feature accurately accounts for player substitutions during games and factors in red card occurrences, ensuring a precise estimation of playtime for every player. |
| Measures of error |
For the training process, well-established error measures for regression tasks were employed. The set ŷ ∈ Ŷ contains the classification values, and the set y ∈ Y represents the actual measured values. 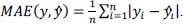 The MAE had the same scale as the measured data and is used for evaluation. We choose MAE as it is robust against outliers and offers intuitive interpretationt. Similar to the MAE, the To calculate the loss, the MSE was computed as follows: 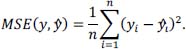 The We use the MAPE for the final evaluation, which is defined as follows: 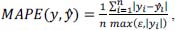 where |
|
|
| Experimental setup |
To streamline our model and ensure its stability (Hansen and Yu, To ensure comprehensive evaluation and ascertain the robustness of our model, experimental analyses were carried out on two datasets: one with reduced features and another containing all features without exclusions. To assess the comparability of our dataset with related work, we calculate the Pearson Correlation of our characteristics with the target value (RPE). This makes it possible to estimate the information value of the features in relation to the target variable (RPE) and thus to estimate the modeling effort of the machine learning model and the deep learning model. In our final dataset, that will serve as input for the machine learning a deep learning models, we discovered heart rate zone 8 and 7 related features to result in the highest correlation with a Pearson Correlation of 0.161 (see |
| Evaluation of machine learning models |
The outcomes of all machine learning models, including their respective best hyper parameter combinations, are displayed in Both machine learning and deep learning models exhibited superior performance on the dataset when excluding the data from soccer matches. Our self-designed deep learning architecture demonstrated notably enhanced results on the dataset without games. The deep learning model performed better when all features were included, whereas machine learning models showed improved performance with reduced features. Feature importance analyses revealed a mean/median feature importance of 0.58/0.59 (±0.19) in our dataset without exclusion (174 features) and 0.93/0.92 (±0.25) in our reduced dataset (108 features), whereas maximum heart rate was the most important feature with a relative importance of 1.81% for the top ten important features for both datasets ( |
| Evaluation of the deep learning model |
For the deep learning model, a hyperparameter study with a grid search in the following parameter ranges was performed: |
|
|
This article aimed to identify which external and internal load parameters correlate with subjective RPE, assess various machine learning models for estimating RPE, and to develop a deep learning architecture for predicting RPE based on objectively measured external and internal load parameters. The main results of our study are that a multitude of objectively assessed external and internal parameters affect RPE (most prominent ones being maximum heart rate, maximum acceleration, and total distance covered in speed zone 10-13 km/h), and that out of the herein investigated machine learning models, the ExtraTree machine learning model outperforms other machine learning models when predicting RPE with a Mean Absolute Error (MAE) of 1.25 (±0.01). Additionally, our designed deep learning architecture performed best with a Mean Absolute Error (MAE) of 1.04 (±0.07) RPE units. The ExtraTree model achieved comparable results on the MSE/RMSE metric (ExtraTree RMSE: 1.63 (±0.04), deep learning RMSE: 1.64 (±0.05)). We found that the results with the dataset that included games were slightly lower compared to the dataset where games were removed. With data from games, we noticed different values than in training sessions, especially for the data related to internal load. We suspect that the total number of games in the dataset was too small for our models to be able to model these deviations. |
| Relationship between objective internal and external parameters with RPE |
Our research contributes to existing literature by expanding upon prior studies (e.g (Bartlett et al., Our research, involving 174 input parameters, demonstrated that RPE cannot be predicted by a single variable; instead, a combination of multiple parameters is necessary. Among the parameters analyzed, maximum heart rate emerged as the most significant predictor of RPE, followed by maximum acceleration, the distance covered within the 10-13 km/h speed zones, the absolute count in heart rate zone 7, and the time spent in the high-speed zone (exceeding 14.4 km/h). |
| Machine learning models and deep learning architecture to predict RPE |
In our study, we explored different machine learning methods to predict RPE using a combination of internal and external load data. The outcomes for the machine learning models revealed that tree-based models achieved the lowest error in predicting RPE, with a MAE of 1.25 (±0.01). It is likely that this improved performance is largely due to the feature boosting process used in tree-based models such as ExtraTree, which enables the extraction of feature details that are critical to the corresponding prediction. In feature boosting, the model adds trees sequentially, with each new tree trained to correct the errors of the ensemble of previous trees, improving the overall accuracy of the model (Geurts et al., Compared to machine learning models, our self-designed deep learning architecture exhibited smaller MAE. However, the ExtraTree machine learning model showed comparable MSE and RMSE to the deep learning architecture (ExtraTree RMSE: 1.63 (±0.04) vs. DL RMSE: 1.64 (±0.05)). When converting the error assessment outcomes from the machine learning and deep learning models into practical insights, our deep learning model seems to be more suitable for more homogeneous athletic groups with fewer outliers. On the other hand, in scenarios involving more heterogeneous athletic groups, which typically include more outliers, the ExtraTree model emerges as the more appropriate choice. Future research should explore the efficacy of the deep learning model proposed in this study using data from a broader spectrum of athletes. This is particularly important because deep learning models generally show improved performance when trained with larger datasets (Goodfellow et al., We were unable to reproduce the error rates of Bartlett et al., who achieved an RMSE of 1.42 (Bartlett et al., |
| Practical considerations |
Athletes and coaches in the domain of soccer may utilize the in this study developed algorithms and trained models to predict RPE with a MAE of 1.15 ± 0.03. This prediction is valuable if the athlete-reported RPE is missing due to low compliance or for comparing the reported RPE with the predicted RPE. Such a comparison is beneficial for identifying discrepancies that might indicate increased athlete fatigue (if the athlete-reported RPE is higher than the predicted RPE) or improved athlete "fitness" (if the athlete-reported RPE is lower than the predicted RPE). Additionaly, coaches might use our algorithms to plan training more precisely in order to avoud differences between planned RPE values by coaches and perceived RPE by athletes (Inoue et al., |
| Strength and Limitations and Future Work |
Our study's strength lies in the meticulous preprocessing of data to eliminate bias in the model training process. This was achieved by over-/undersampling RPE values to ensure an even distribution within the dataset. Furthermore, all models in our study were trained using 5-fold cross-validation, guaranteeing that our reported results are independent of the test dataset. We conducted a thorough evaluation of nine machine learning architectures and a self-designed deep learning architecture, adhering to state-of-the-art concepts for RPE prediction, which bolsters the credibility of our findings. However, our study is limited by its focus on a small cohort of professional soccer players. Future research should encompass a larger pool of soccer players and athletes of other sport domains to enhance the training, potentially improving the performance of machine learning and deep learning models and to further promote generalization and transferability into practice. The broad spectrum of deep learning offers many regression-focused architectures detailed in existing literature. Future studies should assess and compare these various models with our custom-designed approach. Additionally, future research should incorporate other parameters not explored in this study, such as previously reported RPE, using the machine learning and deep learning architectures developed herein. |
|
|
Our main conclusion is that a multitude of external and internal parameters influence RPE prediction in professional soccer players. Out of the 174 investigated parameters, maximum heart rate during training or competition has the strongest influence on RPE. We revealed that the ExtraTree machine learning model, compared to the other investigated machine learning models, achieves the lowest error rates (MAE: 1.15 (±0.03)), is applicable to players beyond those included in this study, and can be executed on almost any currently available laptop. The herein developed state-of-the-art neural network exhibits small error rates (MAE: 1.04 (±0.07)), but due to the high computing power needed, the ExtraTree machine learning model seems to be more suitable in practice. |
| ACKNOWLEDGEMENTS |
The experiments comply with the current laws of the country in which they were performed. The authors have no conflict of interest to declare. The datasets generated during and/or analyzed during the current study are not publicly available but are available from the corresponding author who was an organizer of the study. |
| AUTHOR BIOGRAPHY |
|
| REFERENCES |
|






 Akenhead R., Nassis G.P. (2015) Training Load and Player Monitoring in High-Level Football: Current Practice and Perceptions. International Journal of Sports Physiology and Performance 11.5, 587-593.
Akenhead R., Nassis G.P. (2015) Training Load and Player Monitoring in High-Level Football: Current Practice and Perceptions. International Journal of Sports Physiology and Performance 11.5, 587-593.

